
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Get
- 파이썬
- sql
- 탐색
- 알고리즘
- REDIS
- maui
- dfs
- .net maui
- .net core
- quick sort
- C#
- C++
- BFS
- 백준
- 자료구조
- 큐
- 재귀
- API
- asp.net
- .NET
- 시간복잡도
- Merge Sort
- 정렬
- asp.net core
- 스택
- 도커
- Docker
- docker-compose
- mysql
- Today
- Total
코젤브
1강. 기초 코드 작성 요령 1 본문
[01강 - 기초 코드 작성 요령 I]
0. 시간, 공간 복잡도
1) 시간복잡도
2) 공간복잡도
1. 정수 자료형
1) char
2) short, int, long long
3) Integer Overflow
2. 실수 자료형
-> float(4byte), double(8byte)
1) 실수의 저장/연산 과정에서 반드시 오차 발생
2) double에 long long 범위 정수 함부로 담기 X
3) 실수 비교 시 등호 X
[정리]
정수 자료형
char (signed : -128~127 / unsigned : 0~255)
short (signed : -32768~32767)
int (signed : 약 -21억~21억)
long long (signed : 19자리)
실수 자료형
float : 약 6-7자리
double : 약 15-16자리
0. 시간, 공간복잡도
1) 시간복잡도

위 코드는 연산을 몇번 할까? line5, line6에서 입력받고 더하면서 3~4번의 연산을 진행할 것이다.
즉 1초 내로 충분히 프로그램이 모든 명령을 수행한 후 종료될 것이다.
예를 들어, 시간 제한이 1초라면, 프로그램이 3~5억 번의 연산 안에 종료되어야 한다는 것을 의미.
무슨 말인지 감이 오지 않기 때문에 아래 예시를 보자
위 예시를 보면, n까지 돌려가면서 나머지를 확인하여 0과 일치하면 cnt를 1 증가시키고 있으니 당연히 n에 비례한다는 것을 직관적으로도 확인할 수 있다.
코드 없는 예시를 보자!
만약 N명의 사람이 일렬로 서있는데 이름이 '가나다'인 사람을 찾기 위해 이름을 물어본다면, 얼마나 시간이 걸릴까? (이때 한명의 이름을 물어보고 대답을 듣는데까지 1초가 걸린다)
-> 최선의 경우 1, 최악의 경우 N, 평균으로 N/2만큼 걸릴 것이다.
이때 만약 사람들이 이름 순으로 서있다면?
-> 업다운 게임을 하는 것처럼 중간 사람에게 계속 물어보면 최선의 경우 1, 최악의 경우 lgN, 즉 평균적으로 lgN초가 걸릴 것이다. 즉 lgN에 비례한다. (lg2 = 1)
즉 위에서 우리가 확인했던 내용의 개념을 정의하자면 아래와 같다.
시간복잡도(Time Complexity)
: 입력의 크기와 문제를 해결하는데 걸리는 시간의 상관관계
빅오표기법(Big-O Notation)
: 주어진 식을 값이 가장 큰 대표항만 남겨서 나타내는 방법
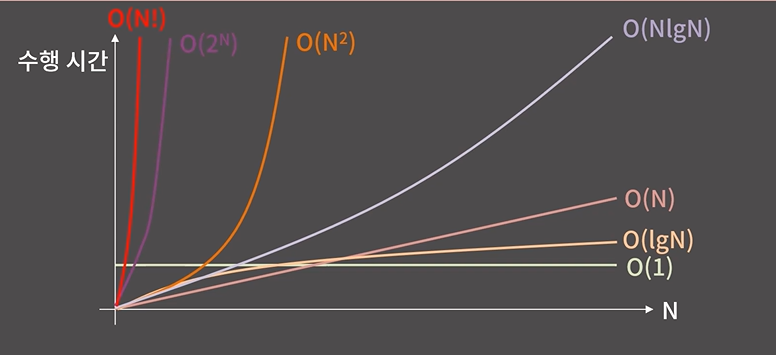
문제에서 대충 1초에서 5초 사이의 시간제한이 주어지기 때문에 문제에서 입력의 크기를 보고 어느 정도의 시간복잡도를 요구하는 지 알 수 있다.
예를 들어 주어진 배열을 크기 순으로 정렬하는 문제!
-> 이는 O(NlgN) 또는 O(N^) 로 해결할 수 있다. N이 1000이하라면 상관 없지만,
만약 100만이라면? 전자는 1초 내로 끝나지만, 후자는 1시간 가까이 걸린다....
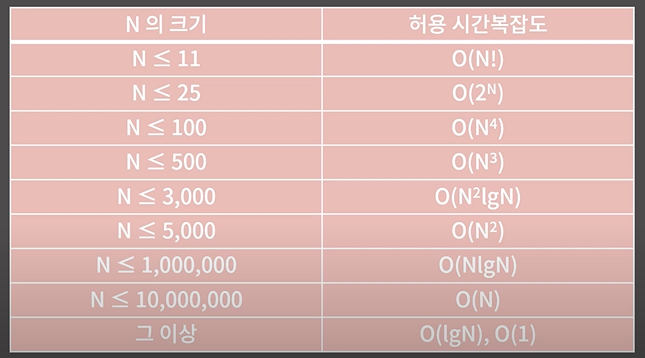
-> 이제부터 시간 복잡도를 고려하면서 문제 풀기 시작하자!!
예제 문제)

#include <iostream>
using namespace std;
int func1(int N); // func1 함수 선언
int main()
{
cout << func1(16) << endl;
cout << func1(34567) << endl;
cout << func1(27639) << endl;
return 0;
}
int func1(int N)
{
long sum = 0;
for (int i = 0; i < N; i++) {
if (i % 3 == 0 || i % 5 == 0) {
sum += i;
}
}
return sum;
}
이 코드의 시간 복잡도는 얼마일까? O(N)

int func2(int arr[], int N) {
for (int i = 0; i < N; i++) {
for (int j = i + 1; j < N; j++) {
if (arr[i] + arr[j] == 100) {
return 1;
}
}
}
return 0;
}이중 for 문으로 확인하기 -> 시간 복잡도 O(N^)
사실 제법 비효율적인 것 같은데요. O(N)의 시간복잡도를 갖게 짤 수도 있답니다.
추후에 배열을 다룰 때 알려준다고 합니당

int func3(int N) {
for (int i = 0; i < pow(N, 0.5)+1; i++) {
if (i * i == N) { return 1; }
}
return 0;
}이게 맞을까?! 정답 코드 보니깐 대충 비슷하당

시간 복잡도는 O(루트N)

int func4(int N) {
int ret = 1;
for (int i = 0; pow(2,i) <= N; i++) {
ret = pow(2, i);
}
return ret;
}흠 이것도 답이 맞을까? 맞긴한데, while 문을 쓰는 게 더 깔끔할지도..
아래는 정답 코드이다.

이 방식의 시간복잡도는 O(lgN) 이다. 역시 내 코드보다 더 깔끔하당..
2) 공간복잡도
공간복잡도 : 입력의 크기와 문제를 해결하는데 필요한 공간의 상관관계
* 대부분 코테에서 시간복잡도 때문에 문제가 생기지 공간복잡도 때문에 문제가 생기는 일은 드물기 때문에
공간복잡도에 대해서는 아래 부분만 기억하자!
512MB = 1.2억개의 int (int 1개가 4byte이므로)
1. 정수 자료형
1) char

1byte는 8bit 이므로 char 자료형의 값은 8개 0/1이 들어가는 칸을 이용해 표현된다.
char에서는 제일 왼쪽이 -2^7이다.
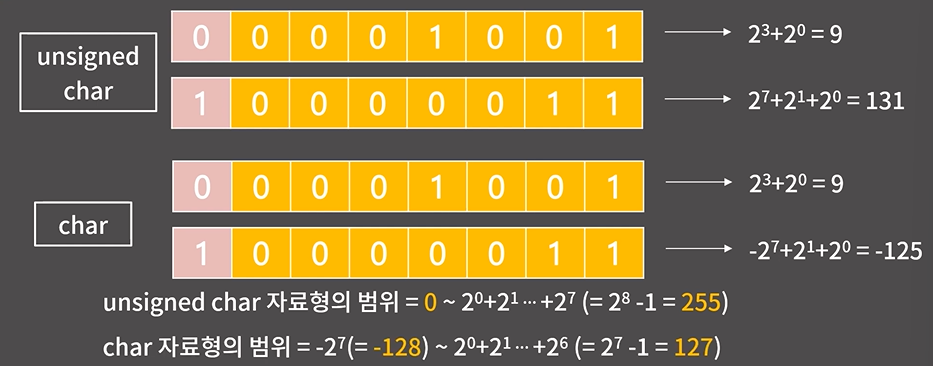
2) short, int, long long
정수 자료형에는 위에서 말한 char 외에도 short, int, long long 자료형이 존재한다.

int가 long보다 연산 같은 부분에서 성능이 좋지만, 80번째 피보나치 수를 구하는 등의 문제에서는.. long을 사용해라
3) Integer Overflow
int가 대충 20억정도까지만 저장할 수 있기 때문에 아래에서 오류가 발생하는 것은 알겠지만, 저 이상한 쓰레기 값은 어디서 나왔는가?

컴퓨터는 시키는대로 계산했기 때문이당... 착한 녀석..... (코쓱)

아래 경우를 보자. 컴퓨터는 시키는대로 계산하기 때문에, 아래 부분을..


이렇게 계산한다! 이것이 바로 Integer Overflow 입니다
이를 막기 위해서는 각 자료형에 범위에 맞는 값을 가지도록 연산을 시키면 됩니당
근데 제법 이게 빈번히 일어나고 찾기도 어렵습니다... 아래 예제를 풀어보세요
아래 3가지 함수 중 Integer Overflow가 발생할 수 있는 함수는 무엇이고, 어디서 나타날까요?
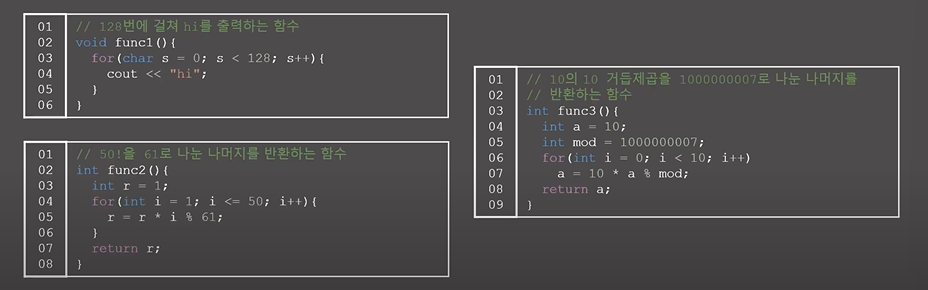
생각해보자. (여러분도 생각해보세요)
func1 함수는 0부터 128번이니 127까지니깐... 문제 없어보이고
func2 함수는 거의 r값이 61보다 작아질테니.. 문제 없을 것 같고
func3 함수의 경우 10억정도로 나누는 거니깐.. 근데 이때 10을 또 곱하니깐 문제가 생기려나..?
뭔지 정확힌 모르겠는데 뭔가 func3에서 문제가 생길 것 같다!
답은...... func1과 func3 입니다!!!
두둥
func1 함수는 s가 127이 된 후, 1이 더해질 때! 128이 되면서 나와야하는데,
의도한 것과 다르게 127에서 1이 더해질 때 -128이 되면서 무한 루프를 돌게 되네요!!! 이런 이걸 생각 못하다니
따라서 이를 해결하기 위해선 char에서 int로 바꿔야 합니다!
func3 함수에서는 a가 10의 9제곱일 때. 10이 곱해지는 순간 범위를 넘어서! integer overflow가 발생
이를 해결하기 위해서는 int를 long long으로 바꿔줘야 합니다.
흐음 역시 어렵네요 눈 크게 뜨고 봐야할듯!!
만약에 문제에서 unsigned long long 범위를 넘어서는 수를 저장할 것을 요구한다면, string을 사용해야 한다.
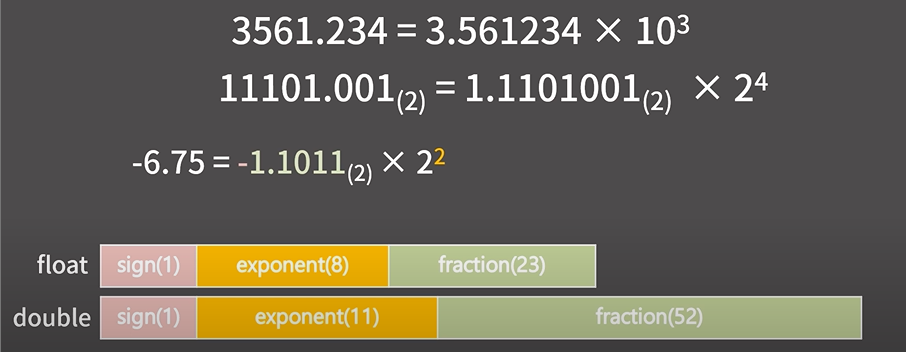
2. 실수 자료형

float (4byte), double (8byte) 가 존재한다.
이제 실수의 성질에 대해 설명합니다!
1) 실수의 저장/연산 과정에서 반드시 오차가 발생할 수 밖에 없다.

유효숫자가 들어가는 fraction field가 유한하기 때문에, 이진수 기준으로 무한소수를 저장하려면 어쩔 수 없이 float은 23bit, double은 52bit 까지만 잘라서 저장할 수 밖에 없다.
0.1은 이진수로 나타내면 무한소수 이므로... 오차가 있는데 이를 세번 더해서 오차가 점점 커져버렸다!
따라서 실수 자료형이 필요하다면 double을 쓰는게 안전하다..!!! (오차범위 보장 때문에)
또한 출력에서 절대/상대 오차를 언급하지 않는 대부분의 문제는 실수를 안쓰고 모든 연산을 정수에서 해결할 수 있는 문제일 것이다!! (아래처럼)

2) double에 long long 범위의 정수를 함부로 담으면 안된다.

double의 유효숫자는 15자리인데, long은 19자리니깐
10^18 +1 과 10^18을 구분하지 못하고 같은 값이 저장된다.
단, 이때 int는 최대 21억이기 때문에 double에 담아도 오차가 생기지 않는다 !!
3) 실수를 비교할 때는 등호를 사용하면 안된다.
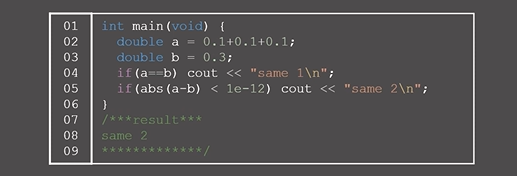
등호 대신에 오차가 10^-12 이하인지 확인해서 처리하기! 1e-12 가 10^(-12) 를 의미하는 것.
정리
정수 자료형
- char
- 범위: -128 ~ 127 (signed char)
- 범위: 0 ~ 255 (unsigned char)
- short
- 범위: -32,768 ~ 32,767 (signed short)
- 범위: 0 ~ 65,535 (unsigned short)
- int
- 범위: -2,147,483,648 ~ 2,147,483,647 (signed int)
- 범위: 0 ~ 4,294,967,295 (unsigned int)
- long long
- 범위: -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 (signed long long)
- 범위: 0 ~ 18,446,744,073,709,551,615 (unsigned long long)
실수 자료형
- float
- 범위: 약 1.2E-38 ~ 3.4E+38
- 유효 숫자 자리수: 6-7 자리
- double
- 범위: 약 2.3E-308 ~ 1.7E+308
- 유효 숫자 자리수: 15-16 자리
참고 강의
[바킹독의 실전 알고리즘] 0x01강 - 기초 코드 작성 요령 I
https://www.youtube.com/watch?v=9MMKsrvRiw4&list=PLtqbFd2VIQv4O6D6l9HcD732hdrnYb6CY&index=2
실습 전체 코드
// 1강
#include <iostream>
using namespace std;
int func1(int N); // func1 함수 선언
int func2(int arr[], int N);
int func3(int N);
int func4(int N);
int main()
{
cout << func1(16) << endl;
cout << func1(34567) << endl;
cout << func1(27639) << endl;
// 함수에 인자로 배열 전달할 때 {} 못 쓴다네
int arr1[] = { 1, 52, 48 };
int arr2[] = { 50, 42 };
cout << func2(arr1, 3) << endl;
cout << func2(arr2, 2) << endl;
cout << "func3" << endl;
cout << func3(9) << endl;
cout << func3(693953651) << endl;
cout << func3(756580036) << endl;
cout << "func4" << endl;
cout << func4(5) << endl;
cout << func4(97615282) << endl;
cout << func4(1024) << endl;
return 0;
}
int func1(int N)
{
long sum = 0;
for (int i = 0; i < N; i++) {
if (i % 3 == 0 || i % 5 == 0) {
sum += i;
}
}
return sum;
}
int func2(int arr[], int N) {
for (int i = 0; i < N; i++) {
for (int j = i + 1; j < N; j++) {
if (arr[i] + arr[j] == 100) {
return 1;
}
}
}
return 0;
}
int func3(int N) {
for (int i = 0; i < pow(N, 0.5)+1; i++) {
if (i * i == N) { return 1; }
}
return 0;
}
int func4(int N) {
int ret = 1;
for (int i = 0; pow(2,i) <= N; i++) {
ret = pow(2, i);
}
return ret;
}'컴공의 일상 > C++' 카테고리의 다른 글
| [Visual C++]C++ 오픈 소스 프레임워크 정적 라이브러리로 사용하기 (0) | 2024.08.13 |
|---|---|
| [Visual C++] C++ 버전 확인 방법 - __cplusplus 199711로만 나오는 문제 (0) | 2024.08.13 |
| 포인터 & 배열 & 벡터(Vector) (1) | 2024.08.09 |
| 0. 프로젝트 시작 및 소스코드 관리 기술 (0) | 2024.08.06 |


